こんにちは。河内です。 最近はデータ基盤の構築も取り組んでいたりします。
社内では他の DWH が使われている事例がありますが、今回の基盤ではデータソースとの親和性や価格面などを考慮し BigQuery で行くことにしました。 BigQuery 上で多くのデータを順次変換してデータを生成するために何らかのワークフローエンジンが必要でした。
社内の他のシステムではワークフローエンジンとして Digdag を採用している例が多いですが、このシステムでは Kubernetes 上でサービスを運用しているため、当初(2020年12月)は Argo Workflow 上でクエリを順次実行することを構想していました。構想中に Dataform が Google に買収され、無料で使えるようになったというニュースが飛び込んできたため、触って感触が良いことを確かめた後、Dataform を使っていくことにしました。
Dataform は SQL パイプラインを定義し、実行するための環境を提供してくれます。 まだまだ使いこなしているとは言えないかもしれませんが、現時点で私が気に入っている点について書きます。
1. SQL をほぼそのまま書けばいいだけ
DWH 上でデータ処理をするには、上流となる table をもとにして view や table を順次作っていくことになります。
Dataform ではこれらの定義が .sqlx に SELECT 文を書くだけなのでとても直感的です。SQLがわかればなんとかなる感があります。
例えば employees から age column の最大値を取り出す max_age view をつくりたい場合は、 max_age.sqlx というファイルを次の内容で作るだけです。
.sqlx という拡張子が示すとおり、ほぼ SQL なのですが、設定など SQL 以外の部分を少し混ぜられる文法になっています。
config {
type: "view",
}
select MAX(age) max_age from employees;
2. ソースコードが Git 管理
ソースコードの編集は主に Web の IDE から実行することになりますが、ブランチを切って PR (MR) を出すことができ、同僚にレビューしてもらってからマージすることができるため、普通のソフトウェア開発に近い感覚でパイプラインを定義できます。
Git ホスティング環境として GitHub や GitLab もサポートされています。我々は GitLab を使っていますので助かりました。
3. branch ごとに隔離された環境
branch ごとに view や table を作成することができるため、開発中の内容が本番の dataset (master/main branch の dataset) に交じることがありません。
database, dataset, table のレベルで branch 名を suffix や prefix としてつけることができます。 どのレベルで隔離するかはお好みだと思いますが、我々は dataset レベルで suffix をつけて隔離する運用をしています。
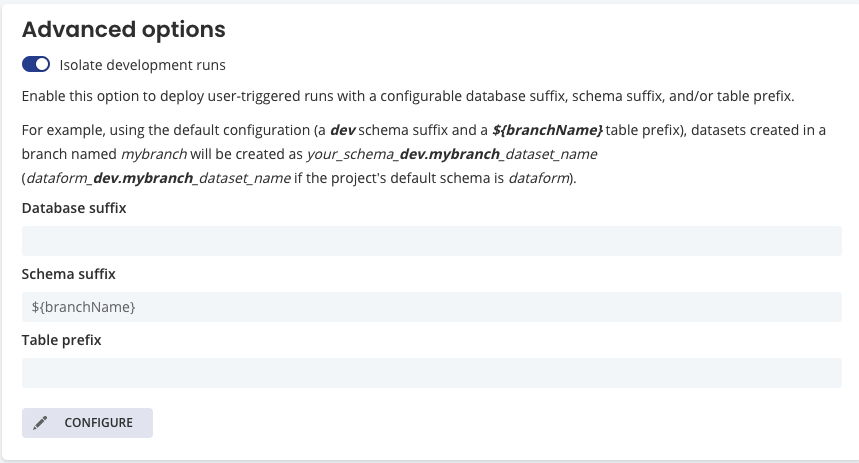
4. スケジュール実行環境がついてる
SQLパイプラインの定期的な実行ができるようになっているので、別途実行環境を用意する必要がありません。大変お手軽で良いと思います。
5. Assertion でデータのチェック
分析用データの品質が悪いと誤った分析結果を招きかねません。 Dataform にはデータの品質をチェックするための assertion 機能があります。
Test data quality with assertions | Dataform
Unique である、あるいは null が無いといった組み込みのチェックがあり、 config.assertions に次のように指定することでチェックできます。
config {
type: "table",
assertions: {
uniqueKey: ["user_id"],
nonNull: ["user_id", "customer_id"],
}
}
select ...
パイプラインの実行時には、uniqueであることや null が無いことをチェックする SQL が実行され、検査の結果、期待を満たさない場合にはパイプラインの実行をエラーとして報告してくれます。
任意の SQL が行を返す/返さないといった形でのチェックもできるため、例えば日次更新されるテーブルに対して、更新日付が新しい行があるか?といったチェックも可能です。
6. Data Lineage
クエリを個別に管理していると、それぞれの View や Table の依存関係がわからなくなることがあります。
Dataform では、.sqlx 中の SQL で元テーブルを ${ref("テーブル名")} という形で参照することで、依存関係を明示できます。
明示することで、依存関係を図示したり、実行順を制御したりすることが可能になっています。
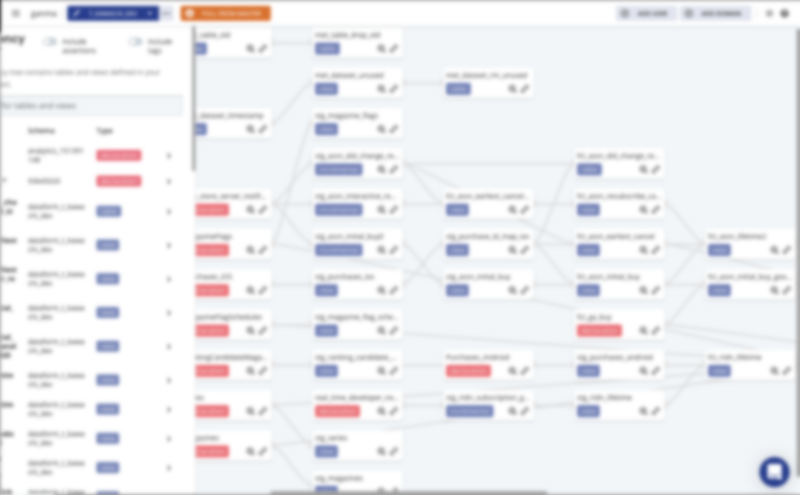
Managing dependencies | Dataform
分析用のクエリだとついつい長い CTE を書きがちですが、この機能のおかげで比較的多めのステップがあっても把握しやすくなっていると感じます(とはいえ多くなりすぎると見づらいので適度な粒度で Table / View を作る必要があると感じており、ここは試行錯誤中です)。
7. JavaScript で SQL を生成できる
少しだけ違う長い SQL を手で書きたくないとは誰しもが一度はおもったことがあると思いますが、そういったニーズには JavaScript で応えることができるようになっています。
.sqlx ファイル内の js { } ブロックや、 .js ファイルで SQL を文字列として生成してそれを利用することが可能であるため、SQL の一部をパラメタライズしたり、繰り返しの多いクエリを短く書く事が可能です。
限界
Dataform は DWH 内の transform に特化したプロダクトであるため、DWH にデータソースを入力するところと、最終的に集計した結果を BI や ML で活用する部分は範囲外です。 DWH 内に限定されるとはいえ、ELT の思想で DWH 内で多くの変換を実行するアーキテクチャではかなり有用だと感じます。
おわりに
Dataform はSQLパイプライン開発を便利にしてくれるツールです。無料で使えるため試しやすいのが良いですね。我々は BigQuery で使っていますが、Snowflake, Redshift, Azure SQL Data Warehouse, Postgres にも対応しているので、該当する DWH をお使いの方は一度試してみてはいかがでしょうか。
似た製品に dbt があるので、そちらもチェックしてみると良いかもしれません。