TL;DR
本日はBigQuery MLの時系列モデルを用いてレポートデータの予測をしてみました。
時系列モデルを使ってモデルの作成からモデルの作成までをSQLライクにできて非常にかんたんでした。
今回はそちらのやり方・内容・料金面についてご紹介させていただきます。
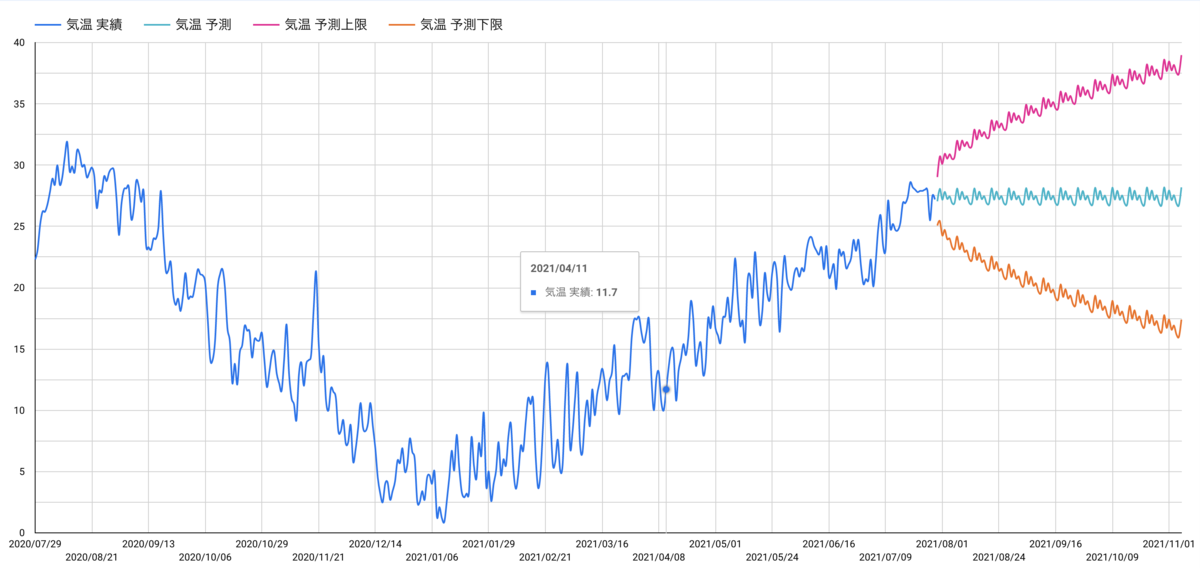
完成したグラフはこちらです。
モデル作成してから利用するまでの流れ
今回はモデルを作成してから、100日後までの気温を予測しました。
-- モデルの作成 CREATE MODEL IF NOT EXISTS `sample_model` OPTIONS( -- MODEL_TYPE: モデルのタイプを設定する。ここでは時系列データ。 -- TIME_SERIES_TIMESTAMP_COL: トレーニングデータのタイムを指定しているカラム -- TIME_SERIES_DATA_COL: 予測する値のカラムを指定する。1つのデータしか予測できない。 MODEL_TYPE = 'ARIMA_PLUS' , TIME_SERIES_TIMESTAMP_COL = 'date' , TIME_SERIES_DATA_COL = 'temperature' ) AS -- トレーニングデータの指定 SELECT date, temperature FROM `sample_reports`
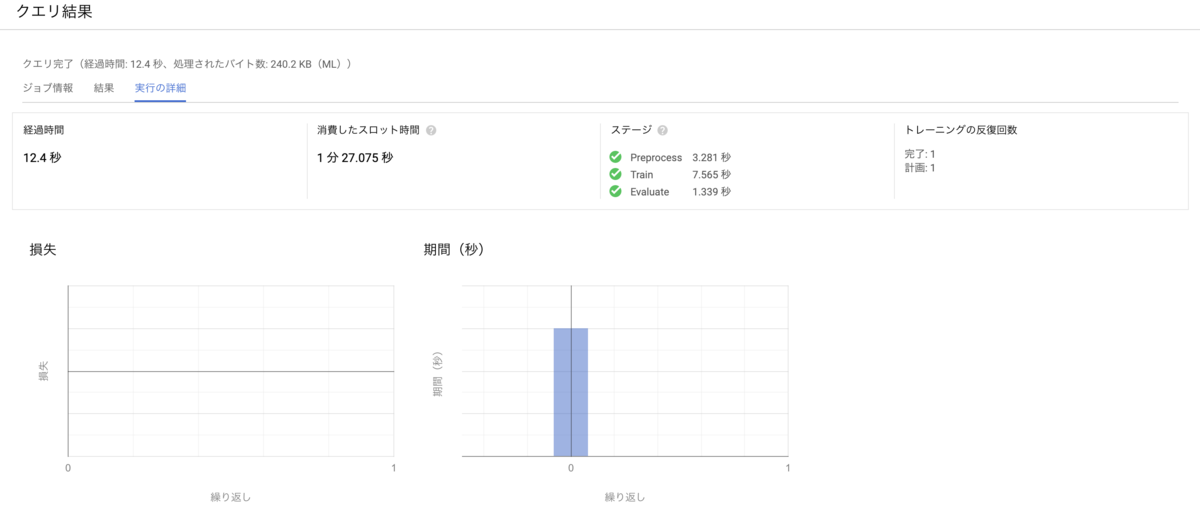
下記のようにクエリ結果が出力されます。
処理時間は5.7 KiBで約12秒かかりました。
前に実験で100GBぐらいの処理を行ったときには約10分程かかりました。
モデルから予測値を取り出す方法は下記のようにFROM句にモデルを記載してあげるだけです。
-- 100日分の気温を予測する SELECT date(time_series_timestamp) AS date, if(time_series_type = 'history', time_series_data, null) history_data, if(time_series_type = 'forecast', time_series_data, null) forcast_data, prediction_interval_lower_bound, prediction_interval_upper_bound FROM ML.EXPLAIN_FORECAST( MODEL `sample_model`, STRUCT(100 AS horizon, 0.8 AS confidence_level) )
注意すべき点
クレンジングされたデータを使ったほうがいいです。
IDやタイムスタンプなどにNULLが入っているとモデル作成時にエラーが発生するので、モデルを作れませんでした。
モデル作成時のクレンジングに関してはKaggleのCause(英語)などが参考になると思います。
お金の話
BigQuery 料金をもとに計算しました。
- CREATE MODEL
- 時系列モデルの場合は $300.00 per TB。モデルタイプによって内容は変わってきます。
- 無料枠は毎月 10 GB までの処理
- 評価、検査、予測(すべてのモデルタイプ)
- $6.00 per TB
- 無料枠は毎月1TBまでの処理
またモデルや予測を実行すると下記のように、処理にかかるリソースの割合を示してくれます。
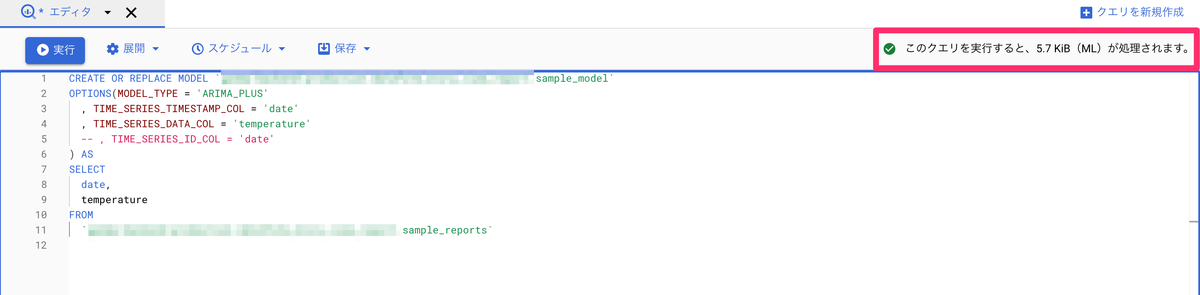
今回の場合過去1年分の天気データを用いてモデルを作成した結果
- CREATE MODEL: 5.7 KiB
- 予測: 42.7 KiB
かかりました。
そのため、毎日1ヶ月モデルの再構築と予測をおこなった場合はおおよそ、
ぐらいで無料枠に収まりました。
逆に、数年分のデータ x IDの量が膨大になってくると料金は爆発的に伸びることが考えられるので、料金を落とすにはデータを集約したり不要なデータの排除を事前に行うことが必要になってくると思います。
感想
BigQuery MLに用意されたテンプレートの時系列モデルを活用することで、データの活用を効率的に行うことができました。
その予測値の精度に関しては確認していないので、ML.ARIMA_EVALUATEなどを用いて確認する部分が課題です。
セプテーニグループは大量のレポートデータを保持しているので、時系列モデルを用いたデータ活用に関しては非常にマッチしていると思いました。